首次配方创建
This deep dive explains what a Recipe is, outlines the differences between Classification and Segmentation, and provides step-by-step guidance on creating a Recipe. It also includes a detailed walkthrough of Image Setup configuration, Template Image capture and Alignment setup, ROI optimization, data collection and AI training, as well as image augmentation configuration.
查看本主题的实际演示: 如何在几分钟内创建一个 segmentation 配方
学习目标
通过本次深度讲解,您将理解:
- what a recipe is
- the difference between classification vs. segmentation – and when to use each
- how to create a recipe
- how to configure Imaging Setup
- how to capture a Template Image and configure the Aligner
- what ROIs (Regions of Interest) are and how to optimize them
- data collection for AI training
- recipe Testing and Validation
What is a Recipe?
- A configured set of instructions that tells the camera how to inspect a specific part or product.
- Defines camera settings, including exposure, focus, and lighting parameters for consistent image capture.
- Includes processing logic such as ROI definitions, Aligner, classification, or segmentation classes.
- Stores input/output configurations to integrate with automation systems for pass/fail or advanced signals.
- Can be saved and reused to ensure consistent inspections across shifts, lines, or facilities.
Classification vs. Segmentation
Definitions
- Classification:在 ROI 中识别对象的类型
- Segmentation:在图像/ROI 中定位和分析区域
Examples
| Image Classification | Image Segmentation | Image Classification | Image Segmentation |
|---|---|---|---|
| What is a sheep? | Which pixels belong to which object? | Is this pizza acceptable or defective? | Where is each pepperoni? |
 |  |  |  |
Key Comparison
| Classification | Segmentation | |
|---|---|---|
| 速度 | 速度取决于 Image Setup 和复杂性。通常在简单设置下高效且快速 | 可以在优化时达到甚至超过分类的速度,特别是在精简模型时 |
| 准确性 | 适用于整体的 pass/fail 或部件类型识别 | 对于 精确缺陷 定位具有更高的准确性 |
| 复杂性 | 简单 的设置与维护;参数较少 | 复杂 – 需要更多数据、标注和调优 |
| 数据需求 | 低 – 需要较少标注的图像 | 中等 – 需要大量具备像素级精确标注的图像 |
| 使用场景 | 部件存在性、方向、基本质量检查、部件是否放入等 | 表面缺陷、微小特征检测、多缺陷检测、计数、测量等 |
创建并导出配方
使用每个配方旁边的 导出配方 按钮来导出单个配方。
![]()
在屏幕顶部使用 导出 按钮一次导出多个配方。

在屏幕顶部使用 导入 按钮来导入配方。

**请记住:**每个配方一次仅支持一种检查类型,分别是 segmentation 或 classification。在开始设置之前,请选择正确的类型。
图像设置
图像旋转

- 作用/功能: 旋转图像(0° 或 180°)。
- 使用情景: 如果相机安装成角度,但希望在界面中显示的图像方向相反。
如果需要将图像旋转 90°,请旋转相机。
增益

- 作用/功能: 以数字方式增加图像亮度(类似相机上的 ISO)。
- 效果:
- 增益越高 → 图像更亮,但会增加 噪声(颗粒感)。
- 增益越低 → 图像更干净,但需要良好的照明。
| 高增益 | 低增益 |
|---|---|
 |  |
| 亮度更高且噪声更大 | 更暗且噪声更少 |
仅在无法调整曝光或照明时才提高增益。
模板图像与对齐
跳过对齐器

- 作用/功能: 在检查过程中关闭对齐步骤。
- 使用情景: 如果部件在图像中的位置和方向始终保持不变。
模板区域

- 作用/功能: 定义用于对齐的模板图像区域。
- 矩形(Rectangle): 绘制一个感兴趣区域(ROI)。
- 圆形(Circle): 绘制一个圆形 ROI。
- 忽略模板区域(Ignore Template Region): 从对齐中排除某些区域,以避免干扰性图案或无关特征。
- 最佳用法: 有助于系统仅聚焦于最具辨识度的部件特征,以实现准确对齐。
旋转范围
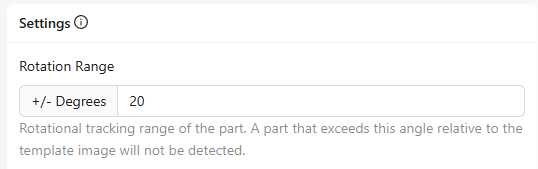
- 作用/功能: 设置系统在将部件与模板匹配时容忍的旋转角度范围(以度为单位)。
- 示例: 将范围设置为 ±20°,允许部件略微旋转但仍可被检测到。
- 调整时机: 如果部件在生产过程中容易旋转,则增大该范围;若取向高度一致,则减小。
灵敏度

- 作用/功能: 控制系统在实时图像与模板之间搜索匹配的细致程度。
- 效果:
- 高灵敏度 → 能检测到更细微的细节,适用于复杂部件。
- 低灵敏度 → 减少误匹配,但可能会错过细小特征。
置信度阈值

- 作用: 设置系统在接受检测时所需的最低置信分数。
- 效果:
- 更高的阈值 → 假阳性更少,但可能错过边界匹配。
- 更低的阈值 → 增加检测数量,但误报风险上升。
从中等开始并根据测试结果进行调整。
尺度不变性

- 作用: 允许系统检测略微大于或小于原始模板图像的部件。
- 何时启用: 如果部件尺寸可能因定位、距离变化或制造公差而略有变化。
实时预览图例

1. 一个可配置的边界框,定义在触发期间需要监控的相机视场(FOV)的特定区域。
- 目的: 确保相机仅聚焦于相关区域,忽略不必要的背景区域。
- 最佳用途:
- 对于移动对象,确保部件始终位于检测区域内。
- 通过减少分析的图像数据量来优化处理速度。
2. 一个可视的红点,显示图像中所有已定义的 ROI(Region of Interest)的中心点。
- 目的: 帮助您对齐并定位搜索区域,相对于部件或相机视图。
3. 绿线表示对象的边缘已被检测到。
如果你看到线条变成红色,请尝试增大 ROI 大小、调整 ROI,或增大灵敏度。

ROI (Region of Interest) 定义与优化
检查类型

- 作用: 定义正在执行的检查类型并将相似的 ROI(Region of Interest)分组。
- 示例: 使用“Holes”来检查零件中孔的存在、尺寸或质量。
- 关键特征:
- 添加检查类型: 为不同的检查需求创建新类别。
- ROI 数量: 显示当前分配给该检查类型的 ROI 数量。
变换
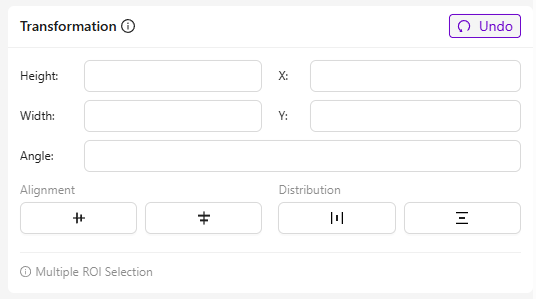
- 作用: 调整所选 ROI 的位置和几何形状,以实现精确对齐和放置。
- 字段及其用途:
- 高度/宽度: 改变 ROI 的大小。
- X / Y: 沿水平(X)和垂直(Y)轴移动 ROI 的位置。
- 角度: 围绕其中心旋转 ROI。
- 最佳用途: 当存在重复模式时加速设置,例如多个相同的孔。
Inspection Regions
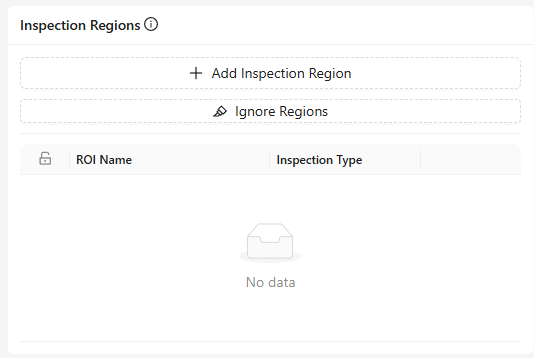
- 作用: 模板图像中定义的所有 ROI(Region of Interest)列表。
- 功能:
- Add Inspection Region: 手动创建一个新的 ROI。
- Ignore Regions: 从处理过程中排除特定区域。
- Edit: 保存、删除或取消。
- Lock Icon: 表示已锁定的 ROI,未解锁前不可移动。
Live Preview Mode
![]()
- 作用: 调整或新增 ROI 后显示的实时反馈。
- 使用场景: 在设置阶段对 ROI 位置和大小进行 fine-tuning 的理想场景。
Test Button
![]()
- 作用: 基于旧图像执行回测以验证修改。
- 使用场景: 将当前结果与先前设置进行比较,以确保准确性和一致性。
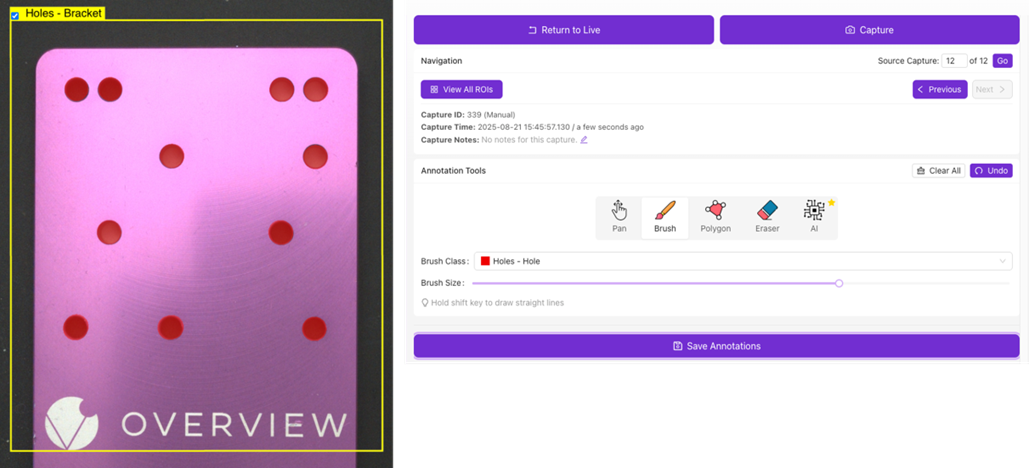
Data Collection and AI Training
定义不同的检查类别,并根据其指定的检查类型对每个 ROI 进行标注(见下方示例)。
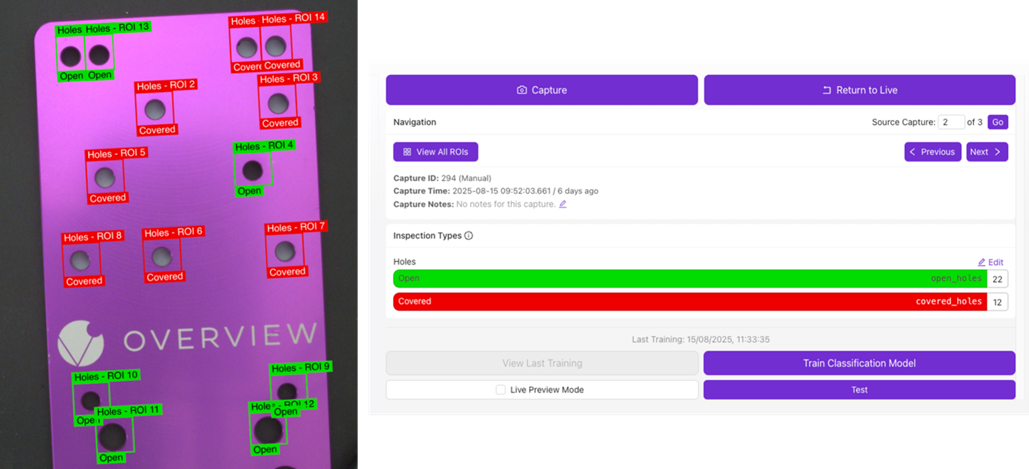
- 使用 Annotation Tools 对图像进行标注。
- 使用 Brush Class 下拉菜单选择要标注的类别。
- 当前每个配方用于分割的类别上限为 10 个。
Importance of good data

-
Garbage In, Garbage Out: AI 模型的好坏取决于所提供的数据。低质量或不一致的数据会导致结果不准确。
-
Diversity Matters: 收集能够代表所有真实世界变体的数据:不同班次、照明条件、部件位置和表面条件。
-
Quality Over Quantity: 较小、干净且标注良好的数据集通常比大型但嘈杂或不一致的数据集表现更好。
Annotation Basics:
- Classification: 将整张图像或 ROI 标注为一个特定类别(例如 “Good”、“Damaged”)。
- Segmentation: 以像素级精度对感兴趣区域进行涂抹、轮廓标注或高亮(例如表面上的划痕位置)。
- Consistency: 在标注时使用一致的规则和定义,以避免训练过程中的混淆。

Common Pitfalls
- Insufficient Data: 样本数量过少将导致欠拟合,进而影响实际应用中的性能。
- Imbalanced Classes: 某一类别(如大量“good”零件但缺少缺陷零件)过度代表,会使模型偏斜。
- Poor Labeling: 标注不准确、不一致或匆忙完成,导致精度显著下降。
- Ignoring Environment Changes: 未在照明、部件朝向或表面条件变化时更新数据集,容易导致精度漂移。
- Not Validating Data: 训练前不进行质量检查,往往造成时间和返工的浪费。
数据增强
图像增强会对您的训练图像进行人工修改,以提高模型的鲁棒性。它们模拟真实世界的变化,如亮度变化、旋转或噪声,从而使模型在不同条件下也能表现良好。
Color Augmentations
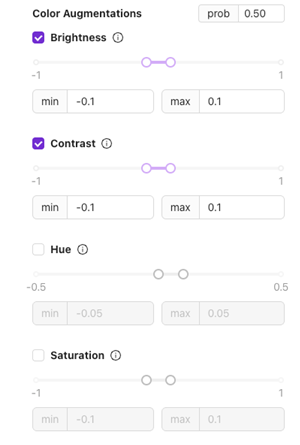
Brightness
- 它是: 调整图像的明暗程度。
- 适用场景: 在生产过程中应对轻微的光照变化。
在稳定设置中使用 ±0.1;若光照变动更大,则应增大该值。
Contrast
- 它是: 改变明暗区域之间的差异。
- 适用场景: 对具有纹理或表面差异的部件非常有用,帮助模型适应视觉差异。
Hue
- 它是: 轻微调整颜色色调。
- 适用场景: 在照明颜色(例如 LED 色温)随时间可能发生变化的场景中很有用。
Saturation
- 它是: 调整颜色的强度。
- 适用场景: 有助于应对照明变化,使图像看起来更黯淡或更生动。
Geometric Augmentations
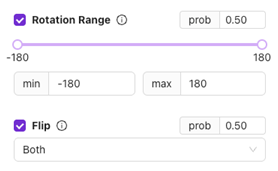
Rotation Range
- 它是: 在设定范围内对图像进行随机旋转(例如 ±20°)。
- 适用场景: 对于可能以稍微旋转的姿态进入的零件。
对于通常固定方向的部件,避免过度旋转。
Flip
- 它是: 将图像水平翻转、垂直翻转,或两者同时翻转。
- 适用场景: 对称部件或搬运过程中方向可能翻转时很有帮助。
Lighting & Color Simulation
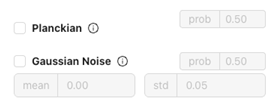
Planckian
- 它是: 模拟色温的变化(例如暖光或冷光照明)。
- 适用场景: 处理不同光源的偏移或工作单元中光源差异。
Gaussian Noise
- 它是: 在图像中添加微小噪声。
- 适用场景: 若生产环境存在微小视觉噪声或相机传感器伪影,可以提高鲁棒性。
Motion Simulation
Motion Blur
- 它是: 模拟在拍摄时零件移动导致的轻微模糊。
- 适用场景: 对于可能出现运动模糊的高速生产线尤为关键。
Probability (prob)
![]()
- 它是: 设置在训练期间应用每种增强的概率。
- 示例: 0.50 = 对任意给定训练图像应用该变化的概率为 50%。
大多数增强从 0.5 开始,并根据实际世界的变动进行调整。
训练参数(Segmentation)
训练参数(也称为超参数)是控制 模型如何从数据中学习 的设置。
学习率

- 定义: 控制在训练过程中模型更新内部权重的速度。
- 数值(0.003): 学习率越高,模型学习越快;但过高可能导致不稳定性或精度下降。
- 滑块范围: 从 10^-4(非常慢)到 10^-1(非常快)。
通常,0.001–0.01 的数值对于分割任务是一个良好的起点。
ROI (Region of Interest) 大小

- 定义: 定义在训练期间使用的图像区域的大小(宽度 × 高度)。
- 未勾选: 默认情况下,模型基于您的数据自动确定 ROI。
- 选中时: 如果你需要一致的输入尺寸(例如,所有图像裁剪为 256×256 像素),可以手动设置宽度和高度。
在数据集中的图像尺寸各不相同时,使用固定尺寸(例如,256×256)可以实现输入的一致性,从而提高稳定性、可重复性,或与已知的模型架构相匹配。
当数据已经具有统一分辨率,或你希望系统基于数据集的特征自动优化 ROI 以获得最佳区域时,让它自动选择。
Number of Iterations (Epochs)

- 定义: 一个 epoch = 对整个训练数据集的完整遍历。
- 数值 (100): 模型将进行 100 次完整遍历。
增加这个数值通常会在某种程度上提高准确性,但需要更长时间。
经验法则: 在训练过程中监控训练损失和验证损失。如果验证损失不再下降,而训练损失仍在下降,这表明模型可能过拟合,应提早停止训练。
Architecture

- 定义: 选择神经网络的大小和复杂性。
- Small: 训练速度更快,对于大多数数据集通常已经足够。非常适合快速试验或较小的数据集。
- Larger models 可以捕捉更多细节,但在小数据集上可能过拟合;而较小的模型在数据有限时更高效并且具有更好的泛化能力。
从 Small 开始,通常就足够,并且在扩展到更大规模之前可以更快地迭代。
External GPU

联系支持获取有关 External GPU 的更多信息。
Training Parameters (Classification)
训练参数(也称为超参数)是用于控制 模型如何从数据中学习 的设置。
Learning Rate

- 定义: 控制模型在训练过程中更新其内部权重的速度。
- 数值 (0.003): 学习率越高,模型学习越快,但过高可能导致不稳定性或准确性下降。
- 滑块范围: 取值范围从 10^-4(非常慢)到 10^-1(非常快)。
通常,0.001–0.01 之间的数值是分割任务的良好起点。
Validation Percent

- 定义: 指定在训练过程中用于验证(测试)的数据集比例。
- 目的: 验证数据有助于在未见样本上监控模型的表现,防止过拟合。
- 取值范围: 0–50%。
常见的选择是 10–20%。
如果设为 0%,所有数据都用于训练,这可能会提高训练准确性,但会使检测过拟合变得更加困难。
ROI (Region of Interest) 大小
- Definition: 定义在训练过程中使用的图像区域的大小(宽 × 高)。
- Unchecked: 默认情况下,模型会基于您的数据自动确定 ROI。
- When Checked: 如需确保输入尺寸的一致性(例如所有图像裁剪为 256×256 像素),您可以手动设置宽度和高度。
固定尺寸(例如 256×256)适用于数据集中图像大小各不相同、但需要输入保持一致性以获得更好的稳定性、可重复性,或与已知模型架构匹配的场景。
当数据本身具有统一分辨率,或您希望系统基于数据集的特征优化 ROI 时,让其自动选择。
迭代次数(Epochs)
- Definition: 一个 epoch 等于对整个训练数据集的完整遍历一次。
- Value (100): 模型将进行 100 次完整遍历。
提高该数值通常会在一定程度上提升准确性,但需要更长的训练时间。
经验法则: 在训练过程中的训练损失和验证损失应同步监控。如果在训练时,验证损失不再下降而训练损失仍在下降,表明模型出现过拟合,应提前停止训练。
架构
- Definition: 选择神经网络的大小和复杂度。
- Small: 训练速度更快,通常足以覆盖大多数数据集。非常适合快速试验或较小数据集。
从 Small 开始,它通常已经足够,并有助于你在扩展规模之前更快地迭代。
| 架构与相机 | 描述 | 建议用途 |
|---|---|---|
| ConvNeXt-Pico | Ultra-light model optimized for speed and low memory use. | 非常适合快速试验或硬件受限的场景。 |
| ConvNeXt-Nano | Slightly larger than Pico; better accuracy with minimal added cost. | 适合小到中等数据集的良好平衡。 |
| ConvNeXt-Tiny | Offers improved accuracy while still efficient. | 适用于中等规模的数据集和较长的训练过程。 |
| ConvNeXt-Small | Most capable variant in this list. Higher capacity and accuracy. | 用于大型数据集或需要最大性能时。 |
External GPU
如需了解更多关于 External GPU 的信息,请联系技术支持。